context + claim
Modern LLMs “think” via explicit chain-of-thought text generation — deferred to post-training, under-leveraging pre-training data. Ouro (named after the recursive Ouroboros) builds reasoning into pre-training through iterative computation in latent space.
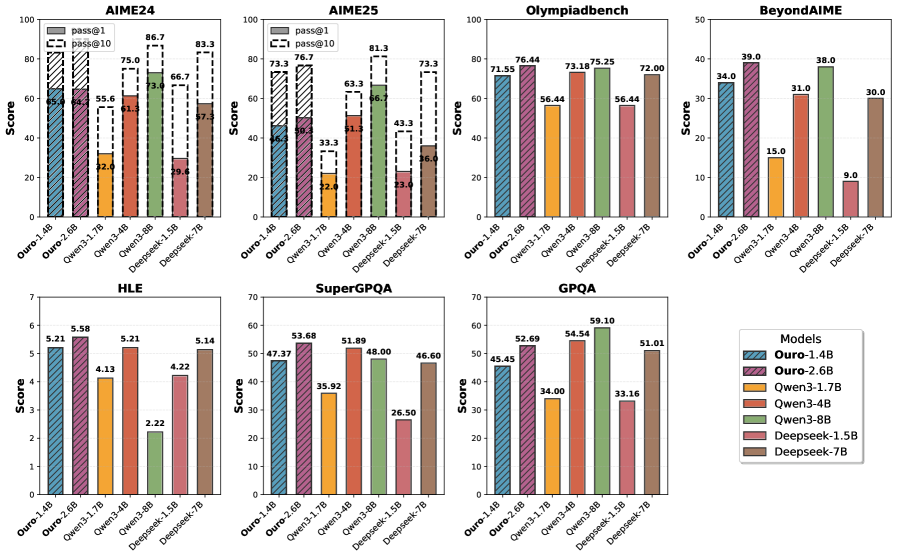
Key claim: 1.4B and 2.6B Ouro models match results of up to 12B SOTA LLMs across benchmarks — achieved via weight-tied looped architecture, not raw parameter scaling.
constraint map
Architecture:
- Parameter-shared looped transformer: same layers applied iteratively
- Exit gate for adaptive computation: model decides when to stop
- Entropy-regularized training: learned depth allocation without collapse
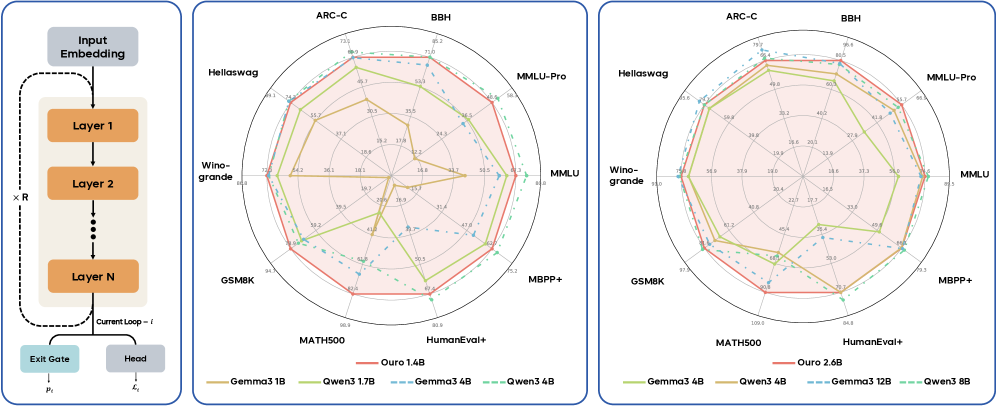
Performance:
- Ouro-1.4B (4 steps) ≈ Qwen3-4B on most benchmarks
- Ouro-2.6B (4 steps) ≈ or > Qwen3-8B on reasoning tasks
- MATH500: Ouro-2.6B scores 90.85 vs Qwen3-8B at 62.30
Training:
- 7.7T tokens total pre-training
- 4 stages: web pre-train → CT annealing → long context → mid-training
- Final SFT for reasoning (math, code, science, chat)
Adaptive Exit:
- Model learns when to stop iterating per-input
- Simple inputs exit early; complex ones use more loops
- Stage II gate training: focused on compute/accuracy tradeoff
my take
This is a genuinely new scaling direction. CoT scales reasoning by extending output tokens. LoopLM scales by deepening internal computation — without adding parameters.
The interesting finding: recurrence doesn’t add knowledge storage (~2 bits/param for both), but dramatically enhances knowledge manipulation — multi-hop reasoning, fact composition.
The failure mode: RL alignment attempts didn’t work. vLLM/SGLang provide fast rollouts via fixed execution paths, breaking LoopLM’s variable-depth computation. Infrastructure gap.
Worth watching: whether LoopLM becomes practical for production reasoning, or remains a research curiosity.
linkage
- LoopLM Paper (arXiv:2510.25741) — explicit vs latent reasoning comparison
- Adaptive Computation Research — early exit mechanisms
- Parameter Efficient Training Methods — small models matching large via architecture