context + claim
October 2025 saw a wave of open-source OCR/document parsing models drop in a single month. The remarkable thing: sub-2B models started beating 200B+ general VLMs on structured document extraction. This isn’t just incremental — it’s a different approach to the problem.
constraint map
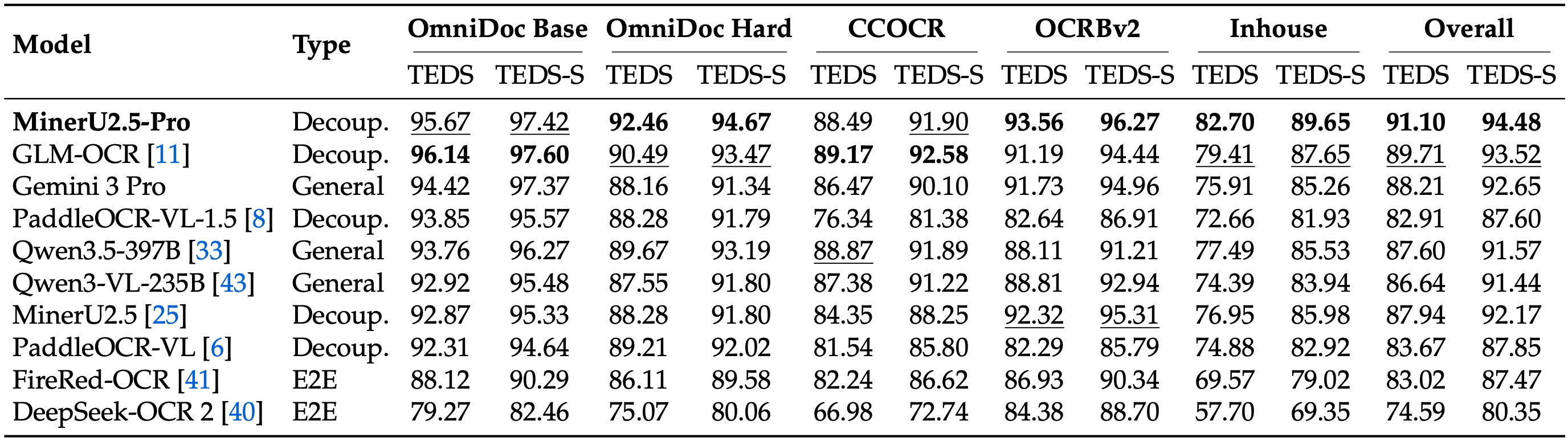
MinerU2.5-Pro (OpenDataLab, April 2026)
- 1.2B parameters (Qwen2VL-based architecture)
- OmniDocBench v1.6 Score: 95.69 — beats Gemini 3 Pro, Qwen3-VL-235B
- Key insight: achieved via data engineering alone — no architecture changes from MinerU 2.5
- Data Engine expanded from 10M → 65.5M training pages
- SOTA on table parsing (TEDS 93.42), formula recognition (CDM 97.29), reading order
- Open source: HuggingFace
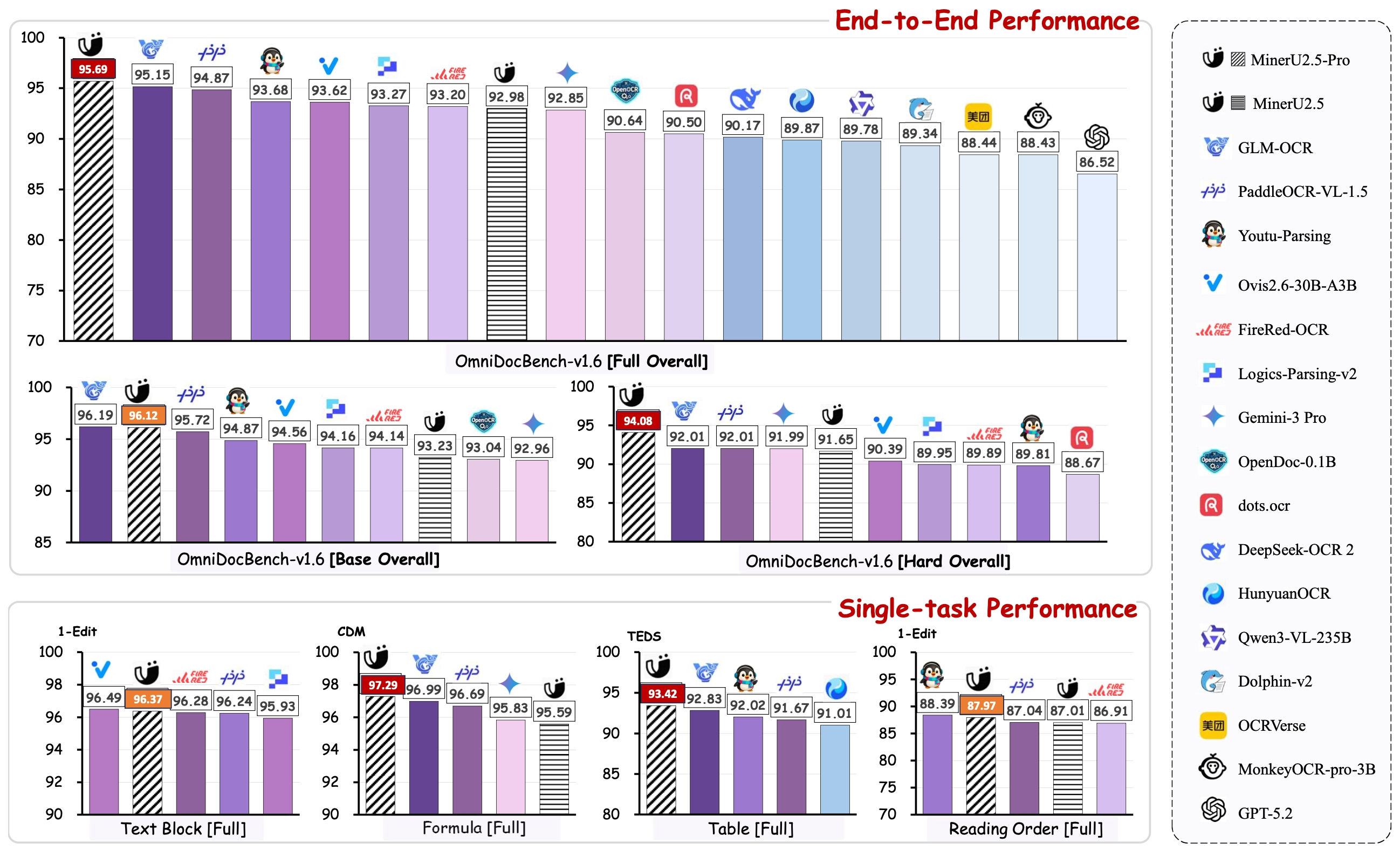
GLM-OCR (Zhipu AI)
- 0.9B parameters
- OmniDocBench v1.6: 95.15
- Strong on standard documents, slightly weaker on hard cases
PaddleOCR-VL-1.5 (Baidu)
- 0.9B parameters
- OmniDocBench v1.6: 94.87
- Good generalization, weaker on complex tables
vs Frontier VLMs
- Gemini 3 Pro: 92.85
- Qwen3-VL-235B: 89.78
- GPT-5.2: 86.52
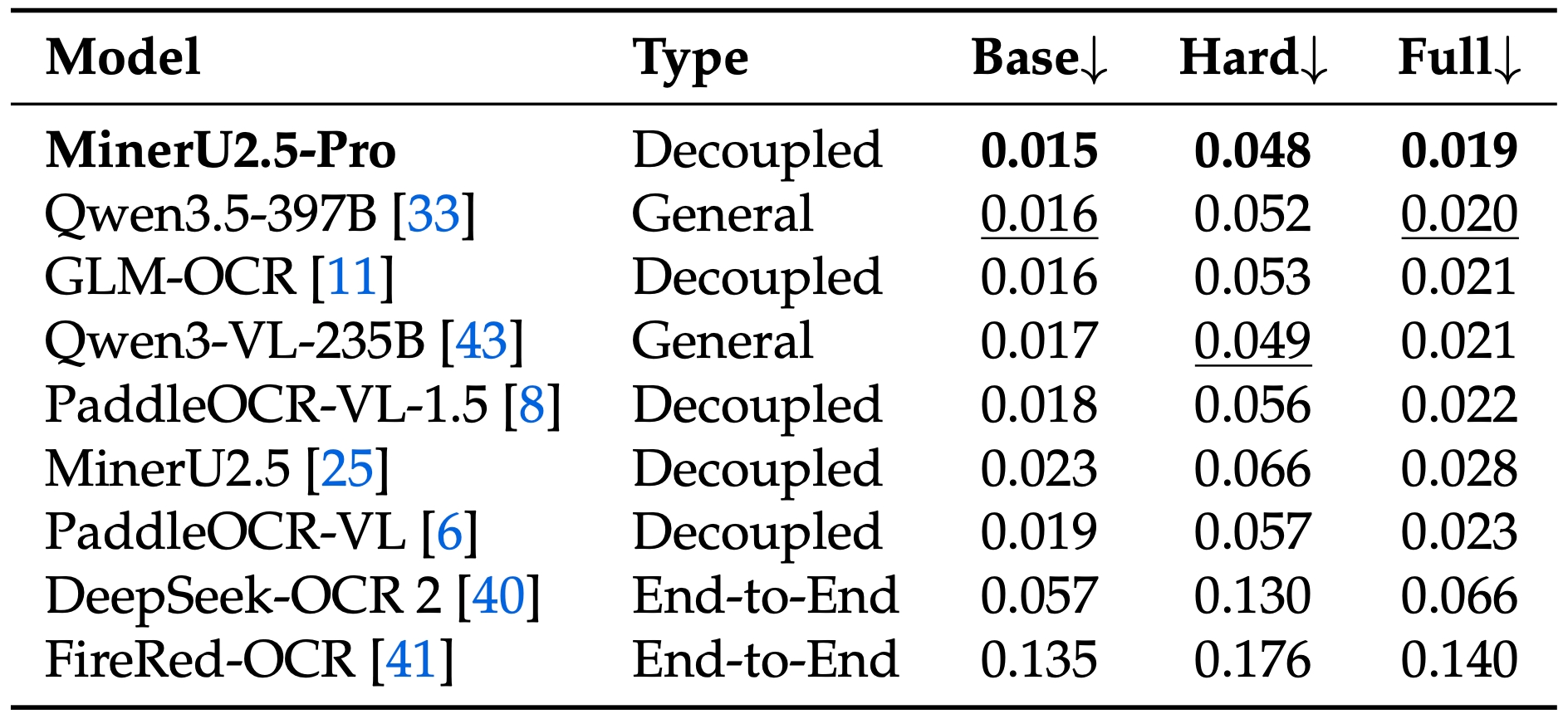
Key benchmark: OmniDocBench v1.6 — corrects matching biases from v1.5, adds Hard subset (296 pages of challenging documents)
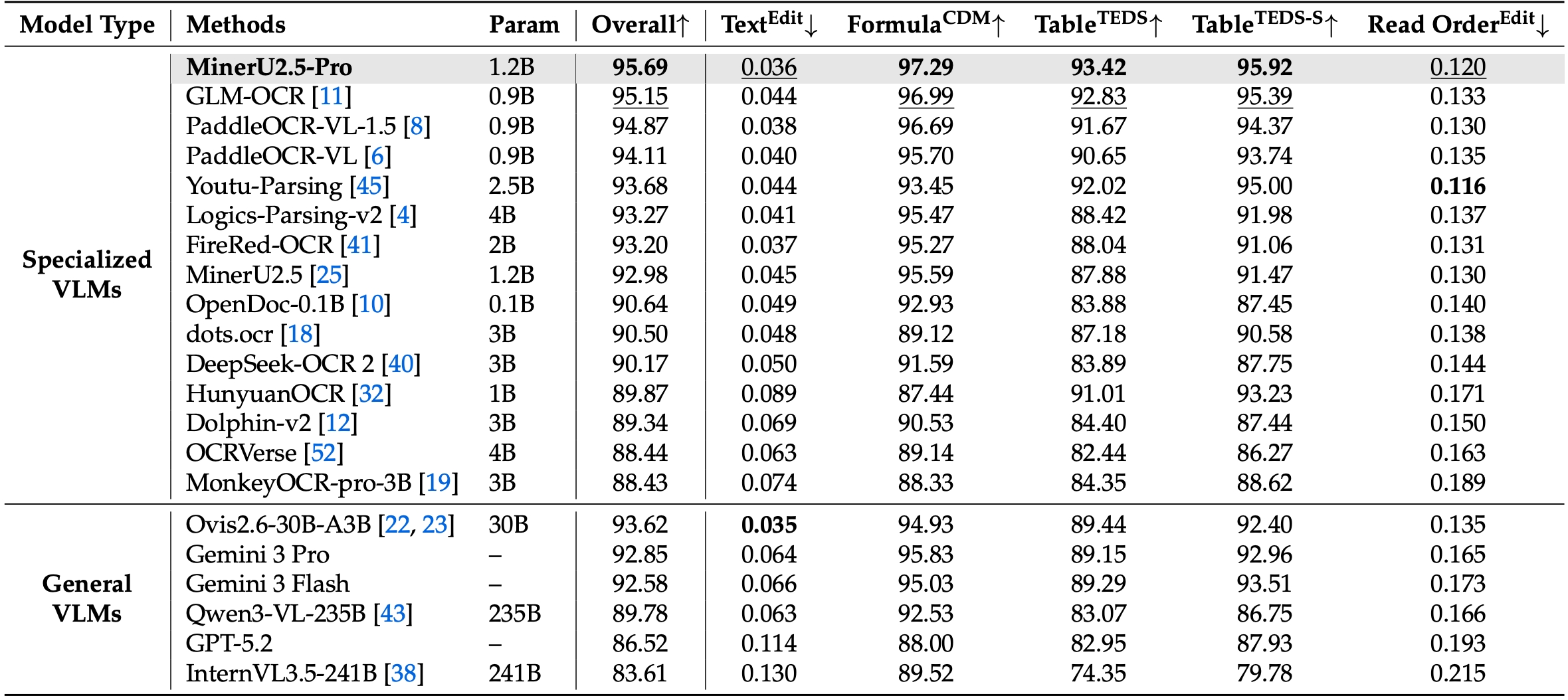
Benchmark Breakdown
Text Recognition (Edit Distance)
Formula Recognition (CDM Score)
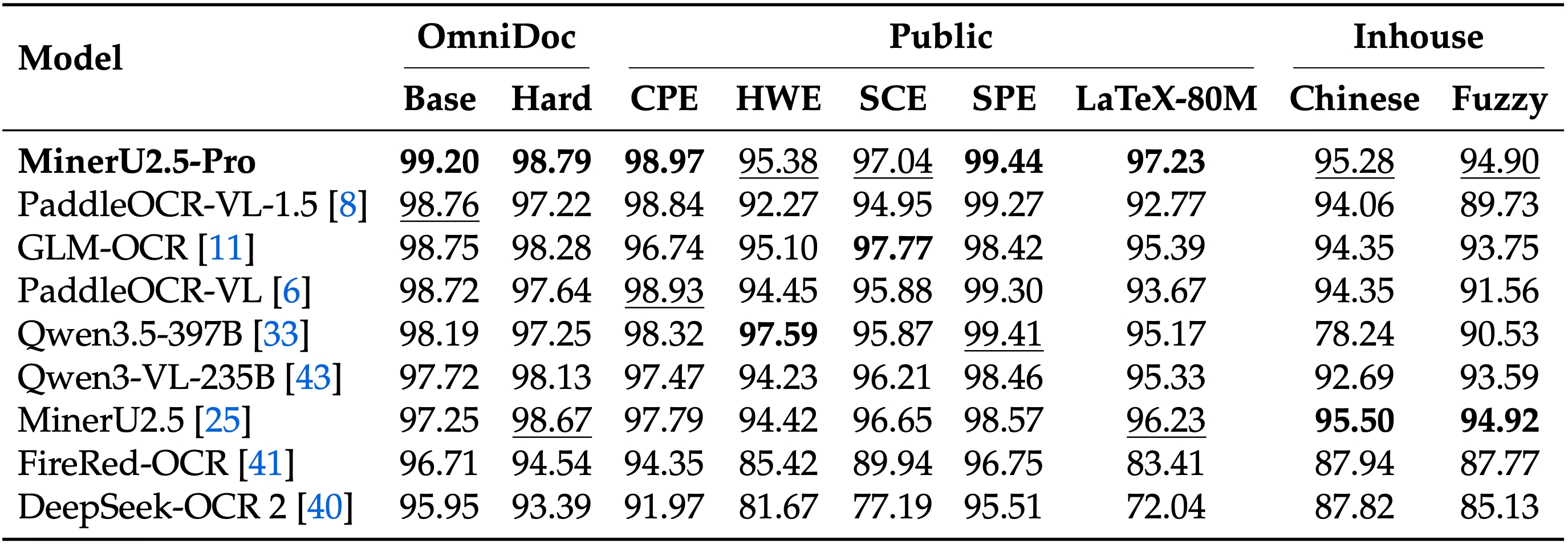
Table Recognition (TEDS Score)
Data Engine Architecture
The breakthrough wasn’t architectural — it was systematic data engineering:
- DDAS (Diversity-and-Difficulty-Aware Sampling): Page-level + element-level sampling
- CMCV (Cross-Model Consistency Verification): Multi-model agreement for annotation quality
- Judge-and-Refine: Render-then-verify for hard samples

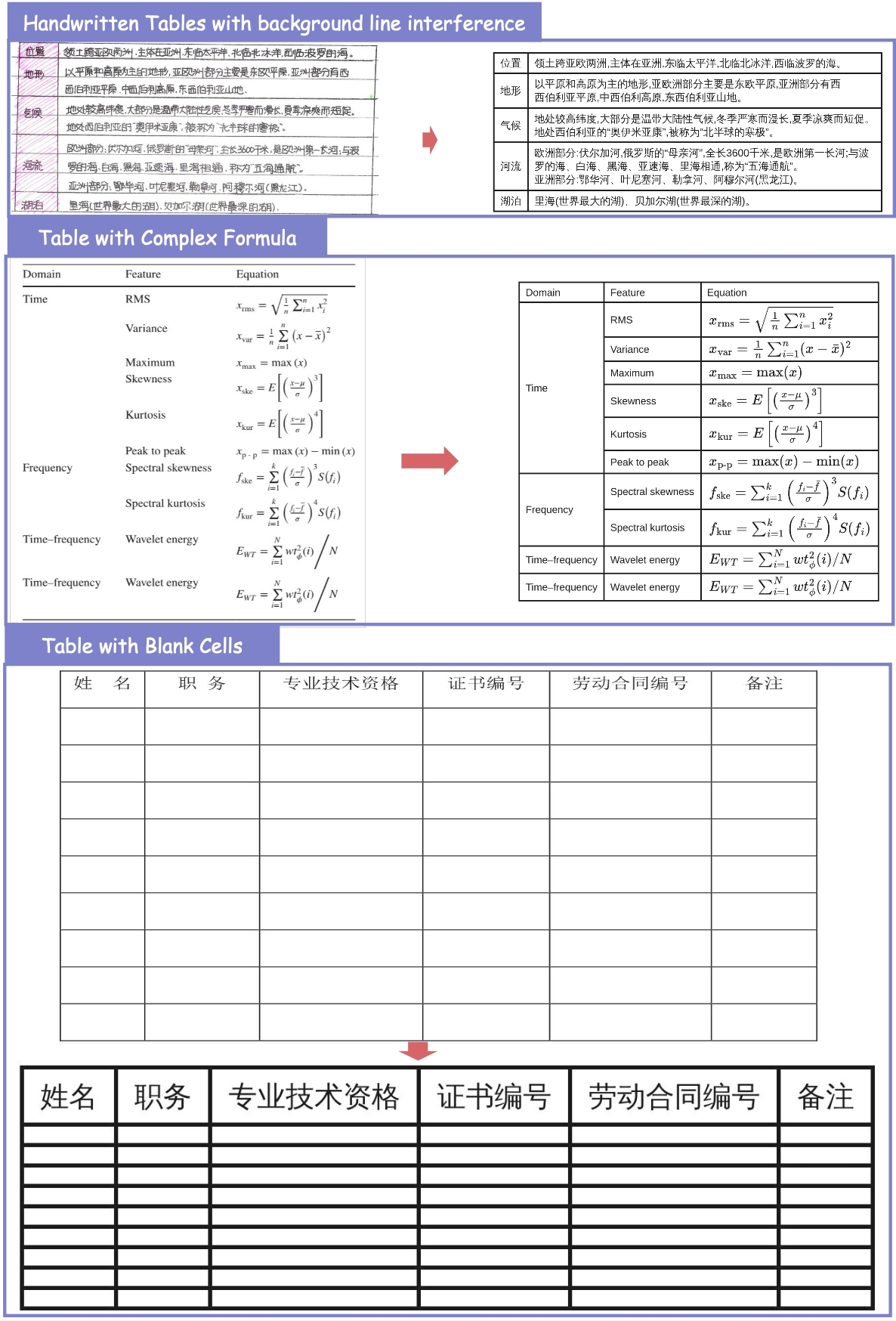
Parsing Examples
Text Recognition

Formula Recognition

Table Recognition
my take
The surprising result: you don’t need 200B+ parameters for document parsing. The bottleneck wasn’t architecture — it was training data quality and coverage.
MinerU2.5-Pro’s approach is instructive: keep the model fixed, throw compute at the data problem. 65.5M pages with systematic quality filtering, difficulty-aware sampling, and cross-model consistency verification for annotation.
The Hard subset reveal is telling — most benchmarks saturate on easy/medium documents. Once you push into complex nested tables, dense formulas, and unconventional layouts, the specialized models dominate. And they do it at 1/100th the parameter count.
For LLM data pipelines and RAG systems, these models are now the practical choice. Fast, cheap, accurate, and open source.
linkage
- llm-data-pipelines — document parsing as preprocessing
- mineru-architecture — decoupled coarse-to-fine OCR approach
- omnidocbench — the new standard for document parsing evaluation